在前面的資料庫文章裡曾介紹過 B-tree,一種平衡的搜尋樹,利用樹狀的結構來達成快速尋找的目的,而且因為是平衡的,所以從 root 出發到每一個樹葉的尋找成本是一樣的,這也是必要的,畢竟資料庫引擎用公平的方式來對待所有的資料.然而,B-tree 的結構並非是 binary 的型式,因此這帶給它很大的彈性可以方便地達成一個完全平衡的狀態.在前幾篇的文章也談過了 binary search tree,若你看過的話,你會清楚地知道 binary search tree 和 binary tree 的不同.在 binary search tree 裡,因為在建立樹的過程中有一個很重要的特性,就是右邊子節點的值大於父節點,左邊子節點的值小於父節點,因此在建立樹或是尋找節點時,到達一個節點時,只需要選擇其中一邊,不是左邊就是右邊,所以也達到 "binary search" 的效果.如前面的文章所說,binary search tree 的特性並不保證樹結構本身是平衡的,所謂的平衡就是其結構會和 complete binary tree 很接近.因為 binary search tree 沒有這樣的特性,因此樹的結構很可能是 "歪" 的.
為了要防止這種 "歪" 的情況,在早期的電腦科學研究裡便出現了許多的點子和做法,其中一個稱為 AVL Tree.這是兩位前蘇聯時代的科學家所發明的方法.發明的時間都是在我們出生之前 (我猜想這部落格的讀者群應該沒人超過 60 歲).首先,先把 AVL tree 的時間複雜度列出來.
Search: O(log n), Insert: O(log n), Delete: O(log n),不論是 average case 或是 worst case 都是一樣的時間複雜度,超級完美的.這也是為什麼在上一篇章的 APCS 考題會拿像 binary search tree 的實做來用,因為就是這麼快.不論是刪除或插入,甚至尋找都是 O(log n),為什麼可以這麼快呢? 接下來將來說重點了.
AVL Tree 是一種 binary search tree 的特例,所謂的特例是指 binary search tree 再加上一些其他的特性之後就能變成 AVL tree.而這一個特性稱為 balance factor.每一個節點上都會有一個 balance factor,它代表的是一個值,其值是右邊子樹的高度減掉左邊子樹的高度.例如:
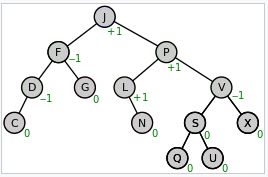 source: Wikipedia
source: Wikipedia
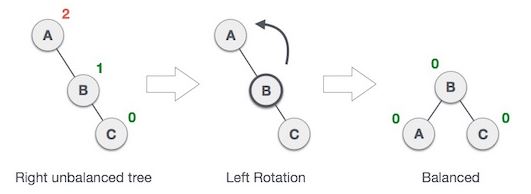 source: www.tutorialspoint.com
source: www.tutorialspoint.com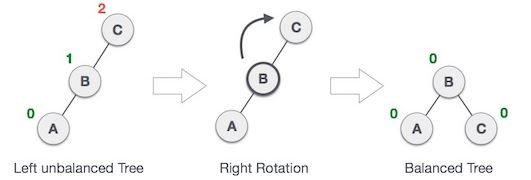 source: www.tutorialspoint.com
source: www.tutorialspoint.com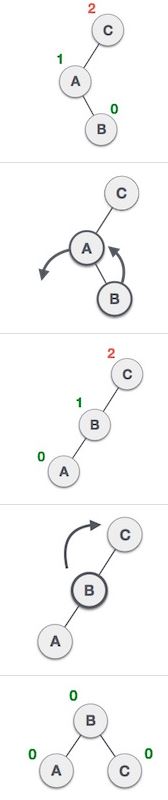 source: www.tutorialspoint.com
source: www.tutorialspoint.com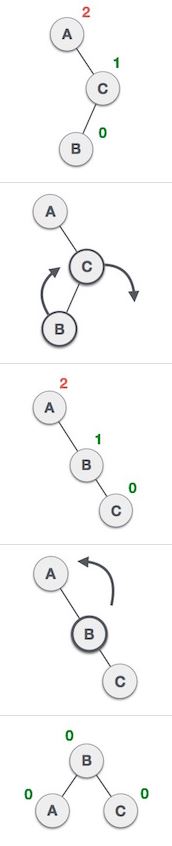 source: www.tutorialspoint.com
source: www.tutorialspoint.com