在大部份的科學領域裡都蠻注重分類 (Classification) 這件事.透過分類,它能幫助我們整理問題,也能整理答案,甚至在不同的問題集合裡找出通用的答案.在人工智慧的領域裡,有一門科目叫模式辨認 (pattern recognition),它應用在影像辨識,人臉辨識,語言辨識等的範圍,其中需要一個重要的技能就是將所要辦認的物件做分類,然後在該分類裡找出合適的對應結果.在這過程中,k-nearest neighbor (KNN) 是一種相對古老且直覺的方法.方法簡單而且能有高準確率,並且不需要所謂的 “訓練”.在人工智慧的領域裡,簡單而言,做的事情就是收集資料,然後依這些資料整理出一個數學模型,未來有新資料出現時,就可以丟入這數學模型加以運算,得出來的結果就是此模型的預測結果.KNN 這方法並不需要所謂的 “訓練” ,也就是說你並不需要從舊資料裡整理出一個數學模型.
KNN 利用資料本身所具備的一些 “自然” 特性來達成辨認的目的.在網路上能找到最常見用來說明 KNN 的範例就是房價. 房價的資料本身就是一個許多資訊的綜合結果,例如包含了環境好壞,面積大小,學區優劣,交通便利,文化觀點等等的因素所綜合起來的結果.想像一下,當你有一份房價資料,裡頭記錄了每一條街某一棟建築物的價格.當你用地圖的方式來呈現時,這在城市的地圖上你可以為已知道建築物標上價格標籤,然後還有許多的建築物尚未知道價格.即便你不懂房地產,當任意從城市的地圖上找到一棟建築物來猜測其價格時,你會怎麼做呢 ? 最簡單直覺的做法就是找附近類似條件的房價來做為參考價格.這也就是 KNN 所採用的概念.
在 KNN 的方法裡,K 是一個大於 0 的數字.以上述房價的例子來看,用來代表你要參考附近 (以距離來算) 多少個房價來做為預測新位置房價的對象.接下來,直接從 Wikipedia 上 KNN 例子的圖來做範例:
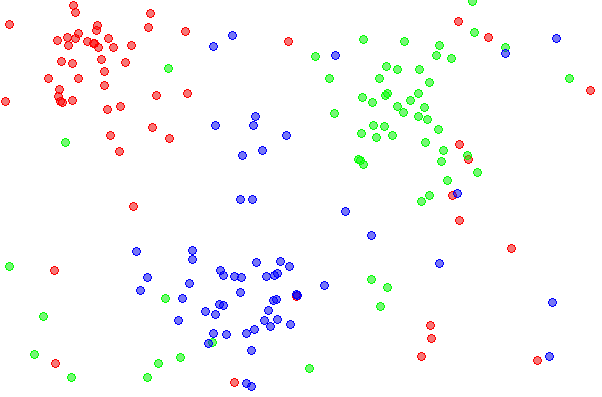
假設上圖是某個城市的房價分佈圖,用顏色來代表不同等級的房價.若採用 K=1 時的分類方法時,可以將地理區域劃出如下的區域:
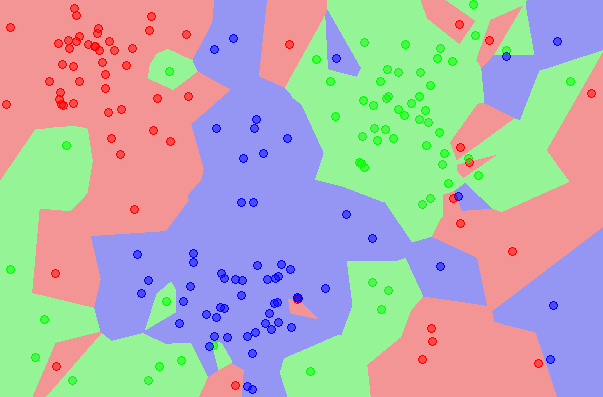
這代表該區域內代表 KNN 方法在 K = 1 時所計算出來的房價.如果 K 值不同時,所得到的區域不會一樣.至於 K 值要取多少才能得到較好的預測結果,這需要更多對資料特性有實務經驗,才能找到適合的 K 值.因此,KNN 要用的好,除了找到一個適合算 “距離” 的公式外,還得對資料有許多實務經驗才行.
剛剛所談的算 “距離” 的公式,這是什麼呢 ? 以上述房價的例子而言,所謂的距離就是預測的房子與資料中最近房子的地理位置上的距離.你可以用直線距離或是真實道路距離來計算,完全依你的情境所需來決定.所以,不同的情況下,計算距離的方式是不一樣的.接下來舉個例子,車牌號碼的辨識已經在許多地方都派上用場了,例如高速公路收過路費,停車場進出入的車牌識別等.車牌識別用 KNN 的方法來進行,該怎麼做呢 ? 首先,我們的資料集合裡一定會有車牌會出現的所有符號,包含數字,英文字母或其他符號等.每一個符號都是一張圖案,而每一個符號在這圖案上所佔用的位置一定不一樣.如下圖是車牌數字的 7 :

當我們用一個 2D array 來代表 7 時,你可以把白色區域用 0 ,而黑色區域用 1,這樣一個 2D array 就可以表達出一個數字的 “長相” 了.會不會有其他的符號有一樣的長相呢 ? 在這個例子裡不會發生,因為每個符號都是不一樣,因此 2D array 裡的 0 ,1 也會不同.
接著,當一個欲辨識的符號進入時,我們怎麼算 “距離” 呢 ? 只要把欲辨識的符號用同樣的方式轉換成 2D array,然後再將這個 2D array 跟我們資料裡所有符號的 2D array 做一個 XOR 的運算 (或是檢查兩個值是否相等).如下面簡單的程式碼 :
只要兩個 2D array 的某個元素不一樣時, diff 就會增加.卻辨識的符號會和所有的符號都進行一次算 “距離” 的運算,最後就選出 diff 最小的,那個就是我們找出的答案.
上述的方法是一個 K = 1 的 KNN 應用,我忽略了許多實作細節,但希望透過這樣簡單的說明能讓沒聽過 KNN 的朋友們知道 KNN 如何應用在車牌辨識上.如前面所說,透過 KNN 方法,我們不需要像 SVM (Support Vector Machine) , CNN (Convolutional Neural Networks) 那樣搞複雜的訓練模型過程就可以得到準確率還蠻高的結果.這樣說並不是說 KNN 比 SVM 或 CNN 強大,只是剛好在簡單的辨識情境裡 (如上述前的車牌辨識) KNN 在 K = 1 時能提供準確率相當高的結果,而且也不用事先訓練模型,也許這能算上是一種數學的奇蹟吧!
KNN 利用資料本身所具備的一些 “自然” 特性來達成辨認的目的.在網路上能找到最常見用來說明 KNN 的範例就是房價. 房價的資料本身就是一個許多資訊的綜合結果,例如包含了環境好壞,面積大小,學區優劣,交通便利,文化觀點等等的因素所綜合起來的結果.想像一下,當你有一份房價資料,裡頭記錄了每一條街某一棟建築物的價格.當你用地圖的方式來呈現時,這在城市的地圖上你可以為已知道建築物標上價格標籤,然後還有許多的建築物尚未知道價格.即便你不懂房地產,當任意從城市的地圖上找到一棟建築物來猜測其價格時,你會怎麼做呢 ? 最簡單直覺的做法就是找附近類似條件的房價來做為參考價格.這也就是 KNN 所採用的概念.
在 KNN 的方法裡,K 是一個大於 0 的數字.以上述房價的例子來看,用來代表你要參考附近 (以距離來算) 多少個房價來做為預測新位置房價的對象.接下來,直接從 Wikipedia 上 KNN 例子的圖來做範例:
假設上圖是某個城市的房價分佈圖,用顏色來代表不同等級的房價.若採用 K=1 時的分類方法時,可以將地理區域劃出如下的區域:
這代表該區域內代表 KNN 方法在 K = 1 時所計算出來的房價.如果 K 值不同時,所得到的區域不會一樣.至於 K 值要取多少才能得到較好的預測結果,這需要更多對資料特性有實務經驗,才能找到適合的 K 值.因此,KNN 要用的好,除了找到一個適合算 “距離” 的公式外,還得對資料有許多實務經驗才行.
剛剛所談的算 “距離” 的公式,這是什麼呢 ? 以上述房價的例子而言,所謂的距離就是預測的房子與資料中最近房子的地理位置上的距離.你可以用直線距離或是真實道路距離來計算,完全依你的情境所需來決定.所以,不同的情況下,計算距離的方式是不一樣的.接下來舉個例子,車牌號碼的辨識已經在許多地方都派上用場了,例如高速公路收過路費,停車場進出入的車牌識別等.車牌識別用 KNN 的方法來進行,該怎麼做呢 ? 首先,我們的資料集合裡一定會有車牌會出現的所有符號,包含數字,英文字母或其他符號等.每一個符號都是一張圖案,而每一個符號在這圖案上所佔用的位置一定不一樣.如下圖是車牌數字的 7 :
當我們用一個 2D array 來代表 7 時,你可以把白色區域用 0 ,而黑色區域用 1,這樣一個 2D array 就可以表達出一個數字的 “長相” 了.會不會有其他的符號有一樣的長相呢 ? 在這個例子裡不會發生,因為每個符號都是不一樣,因此 2D array 裡的 0 ,1 也會不同.
接著,當一個欲辨識的符號進入時,我們怎麼算 “距離” 呢 ? 只要把欲辨識的符號用同樣的方式轉換成 2D array,然後再將這個 2D array 跟我們資料裡所有符號的 2D array 做一個 XOR 的運算 (或是檢查兩個值是否相等).如下面簡單的程式碼 :
只要兩個 2D array 的某個元素不一樣時, diff 就會增加.卻辨識的符號會和所有的符號都進行一次算 “距離” 的運算,最後就選出 diff 最小的,那個就是我們找出的答案.
上述的方法是一個 K = 1 的 KNN 應用,我忽略了許多實作細節,但希望透過這樣簡單的說明能讓沒聽過 KNN 的朋友們知道 KNN 如何應用在車牌辨識上.如前面所說,透過 KNN 方法,我們不需要像 SVM (Support Vector Machine) , CNN (Convolutional Neural Networks) 那樣搞複雜的訓練模型過程就可以得到準確率還蠻高的結果.這樣說並不是說 KNN 比 SVM 或 CNN 強大,只是剛好在簡單的辨識情境裡 (如上述前的車牌辨識) KNN 在 K = 1 時能提供準確率相當高的結果,而且也不用事先訓練模型,也許這能算上是一種數學的奇蹟吧!