延續上一次資料庫的交易文章內容,在一個資料庫系統中同一時間可以執行多個交易 (Transaction).在這同時執行的交易內容中,當遇到共同讀取和寫入同一個物件時,此時便有很大的機會將發生如上一篇文章中提到的資料衝突現象.為了要解決這個現象,資料庫引擎得採取一種策略.以學術的角度而言,策略有好幾種,但比較常見和合理的策略將是本篇文章中將討論的資料鎖定 (Lock).
資料鎖定策略定義兩種鎖,第一種鎖是共享鎖 (Shared lock),也就是當交易對某資料進行讀取動作時,則必需先取得共享鎖,共享的意思也就是其他的交易對同樣資料進行讀取時,也會取得共享鎖,代表這資料只供讀取.所以取得共享鎖的交易可以馬上對資料進行讀取.第二種鎖是互斥鎖 (Exclusive lock),這是當交易對某資料進行寫入動作所需要取得的鎖,其顧名思義,互斥鎖在同一時間只能被一個交易取得使用,如果其他交易也要取得同份資料的互斥鎖,則必須等待.一般而言,我們將共享鎖簡稱為 S lock,互斥鎖稱為 X lock.透過這兩種 lock 便能解決上一篇文章裡所提出的問題.接下來,舉些例子來說明這兩種 lock 如何確保資料鎖定策略能成功.
首先來看下圖的範例,有兩個交易,他們對同一個資料 (A) 先進行讀取動作 (R) 再進行寫入動作 (W)

由於他們將對資料 A 進行寫入,因此他們都需要取得 X lock.假設是 T1 交易先啟動,因此當 T1 啟得 X lock 之後,T2 就得等待.當 T1 完成後 (Commit完成後),對資料 A 的 X lock 就會被釋出,因此 T2 才能得取資料 A 的 X lock,接著 T2 才能執行.因此,真正的執行情況將變成下圖.

如果執行的情況變成 T2 先啟動,則 T1 就必須等到 T2 執行完成後才能取得 X lock 接著執行.因此,不論是那一個交易先執行,另一個交易都必須等待.這是一個很單純的例子.接下來來看一個對多個資料進行讀和寫的例子.

以上是兩個交易 (T3,T4) 對資料 A,B,C 進行動作, 其中 T3 讀取資料 A,讀取和寫入資料 C,而 T4 讀取資料 A,讀取和寫入資料 B.由於 T3, T4都對資料 A進行讀取,所以他們都會取得 S lock,因此可以同時讀取資料A.之後他們分別對不同的資料 (B ,C) 進行寫入動作,因此取得 X lock時是針對不同的資料,所以不用等待對方就能馬上進行寫入動作.

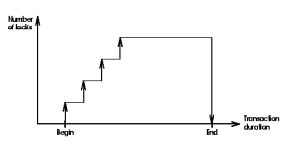
以上所說的方法是採用漸進式的方式來進行資料鎖定,也就是當交易讀取或寫入某資料時,才需要對該資料取得 S lock 或 X lock,而且 S lock 和 X lock 將決定交易是否馬上繼續執行或是需要等待.因此,這樣的方式對資料庫引擎來說是漸漸增加 lock 的數量,然後在交易 commit 或 abort 時,一次釋放該交易所擁有的 lock,就有如下圖一樣:

當 T1 嘗試著取得資料B 的 X lock,結果資料 B 的 X lock 在被 T2 使用中,因此得等到 T2 完成才行,結果 T2 後面有個動作要對資料A 進行寫入,欲取得資料A 的 X lock 時,此時它正被 T1 所使用,需得到 T1 完成才行.因此就進入了一個你等我,我等你的狀態,也是電腦科學領域中常見的 deadlock 問題.資料庫引擎需要有能力來偵測死結的情況,並且要有能力處理死結.以理論上來說,偵測不是難事,資料庫引擎得維護一個 waits-for graph 來對整體系統裡那些交易在等待那些交易完成,透過 waits-for graph 可讓資料庫引擎偵測死結.這對資料庫引擎來說是一項不得不花費的成本,因為要偵測死結的存在,才能對死結的現象進行解決.解決死結最簡單的方法就是將造成死結的交易終止,好讓其他交易可以順利取得 lock,然後再將被終止的交易重新啟動.無論如何,資料庫引擎在這能做的只是事後的預防與問題的排除,若想要盡量避免死結,還需要程式開發人員的配合.交易是程式開發人員所撰寫,因此在寫交易時要儘量避免死結的發生便很重要.有幾個簡單的準則可供參考:
Lock
首先定義上一段文字中所說的 "共同讀取和寫入同一個物件",物件是指交易內容中所感興趣的資料.可能是一筆資料,例如某一個學生的基本資料,可能是符合某條件的資料,例如去年十月份的所有訂單.以邏輯處理而言,通常來說這資料可能只存在於同一個表格,但也有可能存在於多個表格.以實體上而言,資料有可能在同一個 page,但更有可能分散在不同的 page.以邏輯上而言,資料庫引擎可以對一筆資料進行鎖定,也可以對一整個資料表格進行鎖定,或是鎖定某些特定條件的資料.以實體上而言,通常是以鎖定 page 為單位,資料庫引擎比較方便進行鎖定.資料鎖定策略定義兩種鎖,第一種鎖是共享鎖 (Shared lock),也就是當交易對某資料進行讀取動作時,則必需先取得共享鎖,共享的意思也就是其他的交易對同樣資料進行讀取時,也會取得共享鎖,代表這資料只供讀取.所以取得共享鎖的交易可以馬上對資料進行讀取.第二種鎖是互斥鎖 (Exclusive lock),這是當交易對某資料進行寫入動作所需要取得的鎖,其顧名思義,互斥鎖在同一時間只能被一個交易取得使用,如果其他交易也要取得同份資料的互斥鎖,則必須等待.一般而言,我們將共享鎖簡稱為 S lock,互斥鎖稱為 X lock.透過這兩種 lock 便能解決上一篇文章裡所提出的問題.接下來,舉些例子來說明這兩種 lock 如何確保資料鎖定策略能成功.
首先來看下圖的範例,有兩個交易,他們對同一個資料 (A) 先進行讀取動作 (R) 再進行寫入動作 (W)
由於他們將對資料 A 進行寫入,因此他們都需要取得 X lock.假設是 T1 交易先啟動,因此當 T1 啟得 X lock 之後,T2 就得等待.當 T1 完成後 (Commit完成後),對資料 A 的 X lock 就會被釋出,因此 T2 才能得取資料 A 的 X lock,接著 T2 才能執行.因此,真正的執行情況將變成下圖.
如果執行的情況變成 T2 先啟動,則 T1 就必須等到 T2 執行完成後才能取得 X lock 接著執行.因此,不論是那一個交易先執行,另一個交易都必須等待.這是一個很單純的例子.接下來來看一個對多個資料進行讀和寫的例子.
以上是兩個交易 (T3,T4) 對資料 A,B,C 進行動作, 其中 T3 讀取資料 A,讀取和寫入資料 C,而 T4 讀取資料 A,讀取和寫入資料 B.由於 T3, T4都對資料 A進行讀取,所以他們都會取得 S lock,因此可以同時讀取資料A.之後他們分別對不同的資料 (B ,C) 進行寫入動作,因此取得 X lock時是針對不同的資料,所以不用等待對方就能馬上進行寫入動作.
以上所說的方法是採用漸進式的方式來進行資料鎖定,也就是當交易讀取或寫入某資料時,才需要對該資料取得 S lock 或 X lock,而且 S lock 和 X lock 將決定交易是否馬上繼續執行或是需要等待.因此,這樣的方式對資料庫引擎來說是漸漸增加 lock 的數量,然後在交易 commit 或 abort 時,一次釋放該交易所擁有的 lock,就有如下圖一樣:
DeadLock
以上的策略會讓死結 (deadlock) 有機會產生,主要的原因在於 X lock,舉例如下圖:當 T1 嘗試著取得資料B 的 X lock,結果資料 B 的 X lock 在被 T2 使用中,因此得等到 T2 完成才行,結果 T2 後面有個動作要對資料A 進行寫入,欲取得資料A 的 X lock 時,此時它正被 T1 所使用,需得到 T1 完成才行.因此就進入了一個你等我,我等你的狀態,也是電腦科學領域中常見的 deadlock 問題.資料庫引擎需要有能力來偵測死結的情況,並且要有能力處理死結.以理論上來說,偵測不是難事,資料庫引擎得維護一個 waits-for graph 來對整體系統裡那些交易在等待那些交易完成,透過 waits-for graph 可讓資料庫引擎偵測死結.這對資料庫引擎來說是一項不得不花費的成本,因為要偵測死結的存在,才能對死結的現象進行解決.解決死結最簡單的方法就是將造成死結的交易終止,好讓其他交易可以順利取得 lock,然後再將被終止的交易重新啟動.無論如何,資料庫引擎在這能做的只是事後的預防與問題的排除,若想要盡量避免死結,還需要程式開發人員的配合.交易是程式開發人員所撰寫,因此在寫交易時要儘量避免死結的發生便很重要.有幾個簡單的準則可供參考:
- 若非必要,不要為你的 stored procedure 設定成以交易的方式進行.
- 交易應盡量短.如果交易過長,這表示交易將進行更多的讀取或寫入的動作,無形中也增加了死結的機會.因此,最好把交易分割到最小不可分割的單位.過於複雜的商業邏輯由外面的程式邏輯層執行,資料庫只要做基本的資料操作動作.
- 盡量讓交易對資料有相同順序的讀取或寫入.如前面的例子,死結的發生往往在於你等我,我等你的情況.因此,若把資料讀寫的順序盡可能排成一樣,這樣就能大大減少你等我我等你的機會.





 資料來源: 我以前在學校的筆記
資料來源: 我以前在學校的筆記 資料來源: 我以前在學校的筆記
資料來源: 我以前在學校的筆記 資料來源: 我以前在學校的筆記
資料來源: 我以前在學校的筆記