如果你一路追這個系列,從第一集的 interface 是什麼、元件之間怎麼透過 interface 溝通、多型的威力,到後面聊的 單元測試、依賴注入,再到上一集的 介面隔離原則 (ISP),你對 interface 這東西應該已經很有感覺了.
這一集,我想帶你回到第一集那個寄信的程式,那個例子當初只用來說明什麼是 interface,但其實它還藏著更多東西可以挖.這次我們要用它來聊一個很實用的設計模式:Strategy Pattern.它的核心精神,用一句話講就是:把怎麼做 從 做什麼 分離出來.
在這部落格裡,我沒打算寫太多有關物件導向 design pattern 的文章,而許多 design pattern 的做法其實在 interface 有很大的關係.雖然現在很流行用 AI coding tool 來寫程式,但不見得都能做出很好的設計,畢竟許多需求我們不知道該怎麼寫,在沒有好的資料輸入情況下,語言模型也不見得會給你較佳的設計,所以自己還是要多懂一點比較可靠.
第一集的故事是這樣的:你負責寫一個寄信程式,公司各部門都會把信件內容丟給你寄出去.但 A 部門有 A 部門的 email class,B 部門有 B 部門的 email class,如果你為每一個部門都寫一個 SendEmail(),程式碼就會蠢到不行.
當時的解法是:定義一個 IMailContent 的 interface,讓每個部門的 email class 都去實作它.這樣一來,不管是哪個部門的信件內容,都穿上了 IMailContent 這件外衣,你的寄信程式只要認得這件外衣就好,一個 SendEmail() 通吃所有部門.
我當時是這樣描述的:Interface 提供了 object 一種外衣,不同的 email content object 只要有相同的外衣 (IMailContent),都可以在 SendEmail() 裡面使用.一個 object 可以有多個外衣,因此使得物件導向程式設計變得很彈性也很有趣.
第一集那件外衣是穿在 "資料" 上的 —— 也就是信件的內容.今天這一集,我們要把同樣的概念穿到一個完全不同的東西上面 - 寄信這個動作本身.這就是我說的更深一層的應用.
隨著時間過去與業務成長,需求也變複雜了.現在寄一封信這件事,有好幾種不同的做法:
- 有些信走公司自己架的 SMTP server (省錢,但量大時容易塞車)
- 行銷部門的大量電子報改用 SendGrid 這類第三方服務 (送達率高、有統計報表)
- 跑在 AWS 上的系統則直接用 AWS SES (跟雲端環境整合得好、便宜)
同樣是寄信,但底層怎麼寄,已經有三種完全不同的方式了.那你會怎麼寫?很多人第一直覺會用以下的程式碼來做,用一個參數告訴程式要走哪一種,然後用 if/else 去判斷.
public class EmailService
{
public void Send(EmailMessage message, string provider)
{
if (provider == "SMTP")
{
// 連到公司自架的 SMTP server
var server = new SmtpServer("mail.mycompany.com");
server.Connect();
server.SendMail(message.To, message.Subject, message.Body);
server.Disconnect();
}
else if (provider == "SendGrid")
{
// 呼叫 SendGrid 的 API
var client = new SendGridClient("API_KEY_HERE");
client.Post("/mail/send", message.To, message.Subject, message.Body);
}
else if (provider == "AWS_SES")
{
// 用 AWS SES 的 SDK
var ses = new AmazonSimpleEmailServiceClient();
ses.SendEmail(message.To, message.Subject, message.Body);
}
else
{
throw new ArgumentException("不支援的寄信方式");
}
}
}
這程式能跑,乍看之下也沒什麼大問題.但這種寫法會慢慢變成一場惡夢.
我們來想一下接下來會發生什麼事.
過了一段時間後,公司又要接一個新的寄信服務,比如說 Mailgun.你怎麼辦? 你只能把 Send() 這個 method 再打開,塞進一段新的 else if.再過半年又來一個,你又得打開它,再塞一段.這個 method 就像吹氣球一樣,越長越大,最後變成一坨幾百行、沒人敢碰的怪物.
這裡有幾個很實際的問題:
問題一:每次新增都要動到舊的程式碼.你只是想加一個新的寄信方式,卻被迫去改一個已經在正常運作的 method.每改一次,就有機會手滑改壞旁邊那些原本好好的邏輯.本來只想加東西,結果把別人的功能弄爆了,這種事在工程界天天上演.軟體設計裡有個很有名的原則叫做開放封閉原則 (Open-Closed Principle),講的就是 "對擴充開放,對修改封閉",理想的狀況是,要加新功能時用加新檔案的方式,而不是去改舊檔案.這個 if/else 的寫法剛好完全違反了這件事.
問題二:所有寄信方式全部攪在一起.SMTP 的連線邏輯、SendGrid 的 API 呼叫、AWS SES 的 SDK 操作,三套八竿子打不著的程式碼,硬是被塞在同一個 method 裡面.它們各自有各自的細節、各自的相依套件,現在全部纏在一起,光是讀都讀得很累.
問題三:根本沒辦法好好測試.還記得我們在前面的文章聊過 interface 跟單元測試的關係嗎?現在這個 Send() 你要怎麼測?你想測 SendGrid 那段邏輯有沒有正確組出參數,結果你一呼叫 Send(),它就真的去連 SMTP server 或真的去打 AWS 的 API 了.測試環境哪來這些東西? 這個 method 把決定用哪種方式 跟 實際去寄 死死綁在一起,導致它幾乎無法測試.
講到這裡,解法其實已經呼之欲出了.既然這些寄信方式做的是同一件事 (寄信),只是做法不同,那我們是不是可以幫它們設計一件共同的外衣? 此時又回答了 interface 的本質了.沒錯,這就是 interface 出場的時候了.我們先問自己一個問題:不管是 SMTP、SendGrid 還是 AWS SES,它們共同的行為是什麼?
答案很簡單:把一封信寄出去.就這樣.於是我們可以定義這樣一件外衣:
public interface IEmailSender
{
void Send(EmailMessage message);
}
這件外衣只描述了一件事: 我會寄信,你給我一個 EmailMessage,我就把它送出去.至於是怎麼送的?外衣不管,那是各家自己的事.
接著,讓三種寄信方式各自去實作這件外衣,一種一個 class 如下所示
public class SmtpEmailSender : IEmailSender
{
public void Send(EmailMessage message)
{
var server = new SmtpServer("mail.mycompany.com");
server.Connect();
server.SendMail(message.To, message.Subject, message.Body);
server.Disconnect();
}
}
public class SendGridEmailSender : IEmailSender
{
public void Send(EmailMessage message)
{
var client = new SendGridClient("API_KEY_HERE");
client.Post("/mail/send", message.To, message.Subject, message.Body);
}
}
public class AwsSesEmailSender : IEmailSender
{
public void Send(EmailMessage message)
{
var ses = new AmazonSimpleEmailServiceClient();
ses.SendEmail(message.To, message.Subject, message.Body);
}
}
看到差別了嗎?原本那一大坨 if/else,現在被拆成了三個各自獨立、乾乾淨淨的 class.每個 class 只專心做好自己那一種寄信方式,互不干擾.SMTP 的歸 SMTP,SendGrid 的歸 SendGrid,誰也不認識誰.
這裡的每一個 class,就是一個策略 (strategy).SmtpEmailSender 是一個策略,SendGridEmailSender 是另一個策略,AwsSesEmailSender 又是一個策略.它們穿著同一件外衣 (IEmailSender),但裡面各做各的.
外衣定義好了,策略也都實作好了,那真正使用它的主程式會變成如下:
public class EmailService
{
private readonly IEmailSender _sender;
public EmailService(IEmailSender sender)
{
_sender = sender;
}
public void SendWelcomeEmail(string userEmail)
{
var message = new EmailMessage
{
To = userEmail,
Subject = "歡迎加入!",
Body = "感謝你的註冊,很高興認識你..."
};
_sender.Send(message); // 注意:EmailService 根本不知道背後是 SMTP 還是 SendGrid
}
}
請你仔細盯著那行 _sender.Send(message) 看.EmailService 在做的事情,是準備好一封歡迎信,然後寄出去.它從頭到尾完全不知道這封信是透過 SMTP 寄的,還是 SendGrid 寄的,還是 AWS SES 寄的.它只認得 IEmailSender 這件外衣,知道這東西會寄信,這樣就夠了.
這就是把怎麼做從做什麼分離的真正意思:
- EmailService 負責的是做什麼 -> 寄一封歡迎信
- 各個 Sender 負責的是怎麼做 -> 用什麼管道、什麼技術去寄
這兩件事,被 IEmailSender 這件外衣俐落地切開了.
現在最爽的地方來了.如果哪天要換寄信方式,程式怎麼改?
// 開發環境,用公司的 SMTP 就好 var emailService = new EmailService(new SmtpEmailSender()); // 要改用 SendGrid?換一件外衣就好,EmailService 一個字都不用動 var emailService = new EmailService(new SendGridEmailSender()); // 改用 AWS SES?也是一樣 var emailService = new EmailService(new AwsSesEmailSender());
就這樣.你想用哪一種,就在建立 EmailService 的時候,丟一件對應的外衣給它穿上去.EmailService 本身的程式碼完全不需要改動.
而且,如果哪天又要接 Mailgun 呢?還記得前面 if/else 版本要把 method 打開來改嗎?現在你完全不用碰任何舊程式碼,只要新增一個 MailgunEmailSender class,讓它實作 IEmailSender 就好.舊的東西一個都不用動,這就是前面提到的 "對擴充開放,對修改封閉".
有沒有覺得這個換外衣的感覺,跟第一集很像? 第一集是各部門的信件內容穿上同一件外衣,讓寄信程式通吃.這一集是各種寄信方式穿上同一件外衣,讓主程式自由替換.同一個概念,一個套在資料上,一個套在行為上.這就是 interface 的威力,它不只能描述資料長什麼樣,更能描述一個東西會做什麼動作.
如果你有看第六集講依賴注入 (DI) 的那篇,看到上面那個建構式應該會會心一笑.沒錯,Strategy Pattern 跟 DI 根本是絕配.
EmailService 透過 constructor 接收一個 IEmailSender,這完全就是建構式注入 (Constructor Injection) 的標準做法.實務上你根本不會手動去 new 那些 sender,而是交給 DI 容器處理.例如在 ASP.NET Core 裡,你可以這樣設定:
// 整個專案要用哪種寄信策略,集中在這裡決定 builder.Services.AddScoped<IEmailSender, SendGridEmailSender>();
之後所有需要寄信的地方,只要在建構式裡寫上 IEmailSender,DI 容器就會自動把 SendGridEmailSender 注入進去.哪天要換策略? 改這一行就好,整個專案其他地方完全不用動.策略的 "選擇" 被收斂到了一個地方,乾淨又好管理.
看到這裡,比較敏銳的你可能會皺眉頭:「等等,你只是把那串 if/else 搬到別的地方去了吧? 總得有人決定要用哪個策略吧!」 問得好,這是個很重要的問題.答案是:對,那個判斷還在,但它被移到了一個正確的地方,而且只剩一個.
差別在哪?原本的 if/else 散落在核心的寄信邏輯裡面,每次寄信都要跑一次判斷,而且判斷跟實作攪在一起.現在如果你真的需要在 runtime 根據 configuration 來決定用哪個策略,你可以把這個判斷集中在一個地方,通常是程式啟動時的設定處或是一個專門的 factory,如下所示:
public IEmailSender CreateSender(string provider)
{
return provider switch
{
"SMTP" => new SmtpEmailSender(),
"SendGrid" => new SendGridEmailSender(),
"AWS_SES" => new AwsSesEmailSender(),
_ => throw new ArgumentException("不支援的寄信方式")
};
}
關鍵的差異是:這個判斷現在只出現在一個地方,而且它只負責挑策略,挑完就退場了.真正在做事的 EmailService 依然乾乾淨淨,完全不受影響."選擇策略" 跟 "執行策略" 這兩件事被分開了,這才是重點.這跟原本那種每個 method 裡都重複一份判斷、判斷跟實作糾纏不清的狀況是天差地遠的兩回事.
學了一個新工具,最怕的就是看什麼都想用它.所以這裡也誠實講一下,什麼時候適合、什麼時候不適合.當你發現自己符合下面這些情況時,Strategy pattern 通常會幫上忙:
- 同一件事有好幾種不同的做法,而且未來可能還會增加 (像寄信、付款方式、檔案壓縮格式、運費計算規則)
- 你的程式裡開始出現越來越長的 if/else 或 switch,每個分支都是同一類事情的不同做法
- 你希望這些做法可以隨時抽換,或是想針對每一種做法分別寫單元測試
這跟我在之前的文章談 ISP 時的提醒一樣,設計模式都是拿來解決問題的,不是拿來炫技的.先確定你真的有那個問題,再用對應的工具去解.為了用而用,往往比不用還糟.
Hope it helps!
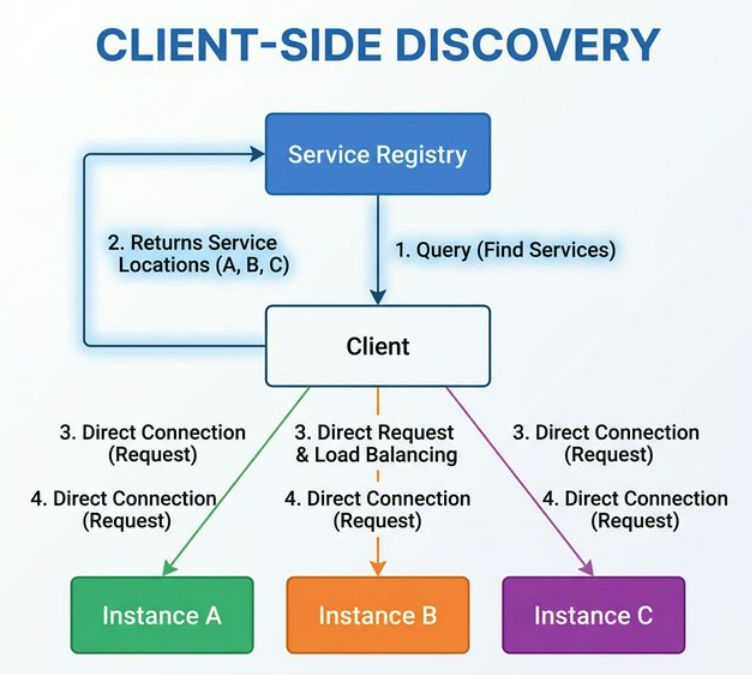 重點:Client 負責查詢 Registry、選擇 Instance、直接呼叫
重點:Client 負責查詢 Registry、選擇 Instance、直接呼叫
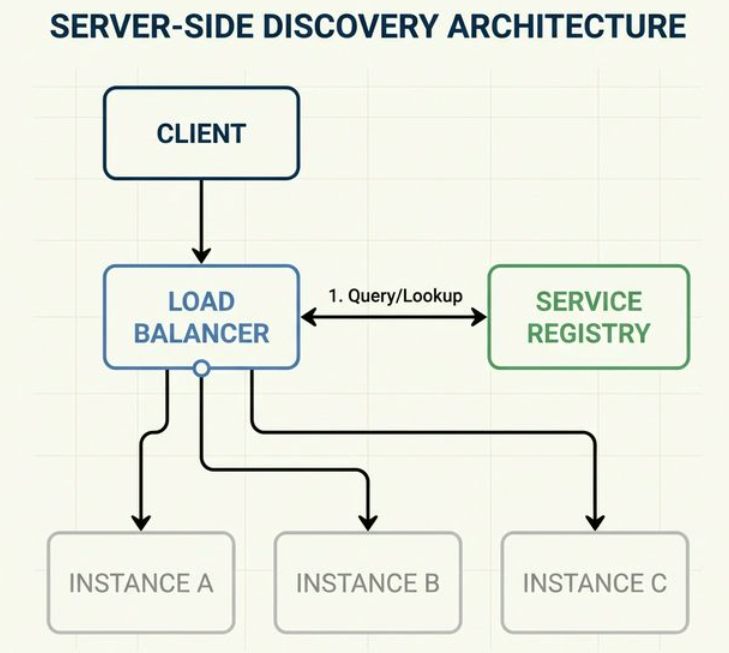 重點:Client 不知道 Instance 位址,由中間層負責路由,多一層 Network Hop,但 Client 邏輯簡單
重點:Client 不知道 Instance 位址,由中間層負責路由,多一層 Network Hop,但 Client 邏輯簡單
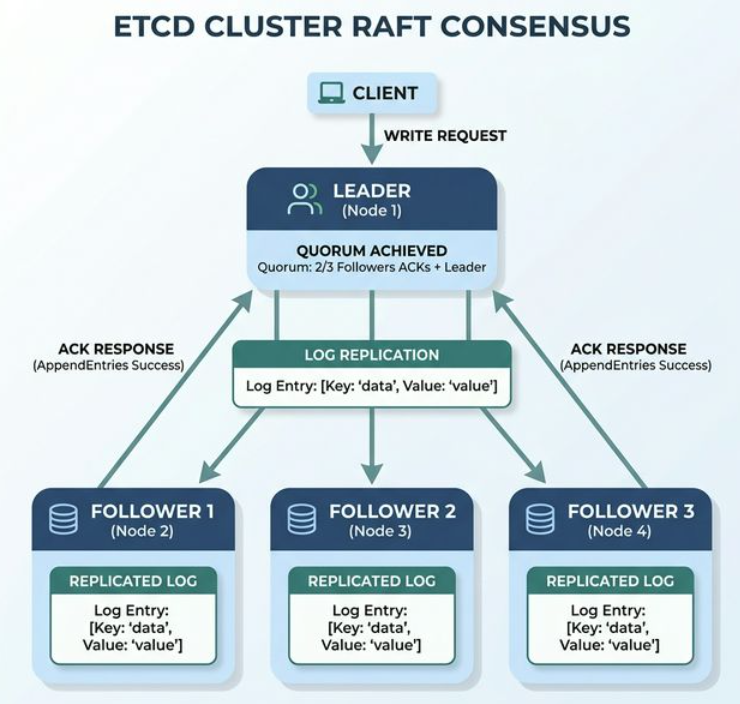 重點:寫入只能透過 Leader,超過半數 (Quorum) 確認即算成功,5 台掛 2 台仍可運作 (3 > 5/2)
重點:寫入只能透過 Leader,超過半數 (Quorum) 確認即算成功,5 台掛 2 台仍可運作 (3 > 5/2)
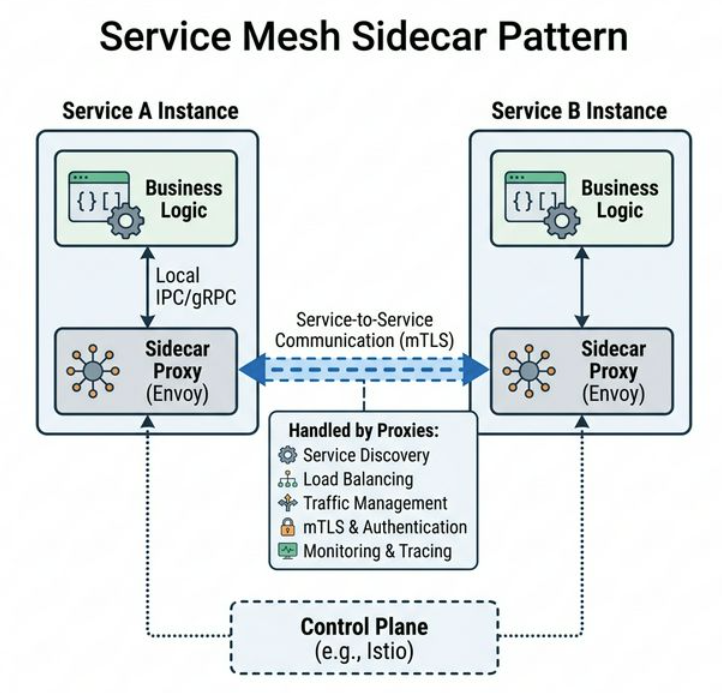 應用只管商業邏輯,網路通訊的一切交給 Sidecar Proxy,所有服務共用同一套基礎設施
應用只管商業邏輯,網路通訊的一切交給 Sidecar Proxy,所有服務共用同一套基礎設施