聽到 hash join 的名字就不難想像這是跟 hash function 有關的處理方式.假設有兩個表格 R 和 S ,其中 R 的資料量比較小,並且也假設電腦的記憶體足夠大能讀入它.此時,可以將 R 一次全部讀入記憶體中,然後對 R 裡面的每一筆資料進行 hash 運算,完成後會得到一個 hash table.另外,假設 S 表格的資料量過大而無法一次全部讀入到記憶體,因此必須分批來處理,所以就一批一批地讀入到記憶體,每一批被讀進來後,就將這一些的資料進行同樣的 hash 運算就能知道是否有符合條件的資料在 hash table 裡面.如果有符合,便將結果暫存到 output page 裡.S 表格資料分批完成之後,就將 output page 回傳給使用者.整個邏輯就像下列的 code
假設 R 表格有 m pages, S 表格有 n pages,上面的動作可以看到 R 和 S 的 page 讀入到記憶體的次數只有 m+n 次,並且迴圈裡的動作是 hash function 的計算和尋找,他們是 O(1),因為跟 R, S 的資料量大小無關.因此整個運作的過程蠻快的.可惜世界不會如此美好,大部份的情況是 R 和 S 往往都遠大於記憶體大小,因此無法將較小的表格一次讀入到記憶體去,於是要再想出其他的方法.有一個不錯的方法叫 Grace Hash Join,它採取兩階段的方式,先對 R, S 的每一筆資料用一個 hash function 做分類,假設分類成 k buckets, 然後再到每個 bucket 裡面再用另一個 hash function 做分類以快速比對資料.整個邏輯如下:
前面用 hash function A 進行 partition 時,其結果是寫入在硬碟中,這稱之為 partition phase.如下圖:
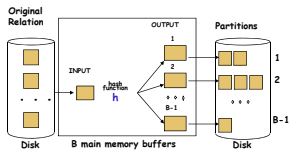
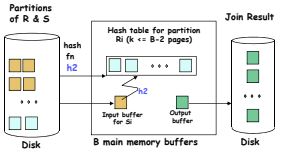
接下來將每個 bucket 依序地讀入到記憶體中來尋找符合條件的資料,這稱之為 probe phase,如下圖:
假設 R , S 分別有 m, n pages,在 partition phase 中,R 所有的 pages 會讀入到記憶體,並且 partition 完成後也會寫入分類好的資料,也是有一樣的 page 數,所以資料庫引擎會有 m 次的讀和 m 次的寫.相同地,對 S 表格而言,也會有 n 次的讀和 n 次的寫,因此在 partition phase 中一共用 2m + 2n 的 page 讀寫.
在 probe phase 中,每個 bucket 都會被讀入到記憶體一次,所以對 R, S 表格來說,一共會有 m + n 次.如果我們不計算寫入 output data 的成本花費,則整個 Grace Hash Join 的動作將用了 3m + 3n 次的 page 讀寫.這個比起上一篇文章裡將的方法大約是 m * n 次要來的好,當 m 和 n 夠大時.
你可以看到依記憶體大小的不同以及資料量大小的不同,採用不同的 join 方式會得到不同的效果.一個好的資料庫引擎便會依照這些條件來決定用何種方式來進行 table join.但不論何種方式,table join 本身就是一個高成本的動作.依此對於超大資料量的表格,不需要 join 的情況是最好的,因此有時為了一些效能成本的考量,才會適當地做一點 de-normalization 的動作讓 table join 可以少見.但這樣做也會產生其他的問題,必須搭配其他的配套措施.
Hope it helps,
0 意見:
張貼留言