在前面的文裡談了有關資料庫 Index,說明了為什麼 index 能加速尋找資料,也說明了 index 有那些種類.在這篇文中,將來簡單談一下 index 所使用的資料結構.
看了前面的文章後,想必你也可以很容易猜出 index 所使用的是像 tree 那樣的資料結構.在前面的文章中也談到了最基本的 tree 資料結構概念.tree 其實在電腦科學的領域裡應用的相當廣泛,不論是學術上或工業界裡,因為 tree 帶來的好處實在很多,但要把 tree 寫出來其實也不是一件很容易的事.不同的應用會衍生出不同的 tree,而在資料庫的 index 所採用的 tree 叫做 B-tree.所謂的 B 就是平衡 balance 這英文字,所以中文你可以用平衡樹來叫它.
B-tree 所指的平衡是指樹的每一個 leaf 到 root 都是一樣的高度,所以整顆樹看起來站的很穩,不會有缺一角的感覺.
為什麼 index 要選擇這樣的 tree 來做為資料結構呢 ? 原因就在於這個 tree 是平衡的,所有 data pointer 都是在 leaf 的地方,也就是說當資料庫引擎在 B-tree 上找資料時,不論它要去那一個 leaf,它所花的成本都是一樣的,也就是樹的高度.所以,以使用者的角度來看,你今天打 select * from student where studentID ='1' 或 select * from student where stuentID='100' ,在 index 上所花的成本都是一樣的.簡單的說就是把所有的資料一視同仁,讓大家都有一樣的存取時間成本.我想這對資料庫使用者來說是件重要的事情,因為你應該不會想讓某些資料有特權來得到較低的存取成本.
接下來的問題就是,我們怎麼會知道這顆樹會一直平衡呢 ? 這並不是資料庫引擎所要擔心的事情,因為保持平衡是 B-tree 本身就要具有的能力,也就是說當一個新的節點新增到這顆樹來後,樹的平衡機制就要啟動來調整樹本身的結構以保持平衡,同樣地刪除節點也是.所以,要實做 B-tree 的重點就是要看保持 "平衡" 的程式碼是不是寫的夠好.在這裡,我就不談論太多保持平衡的細節,若你有興趣知道 B-tree 是如何保持平衡的,可以參考 http://cis.stvincent.edu/html/tutorials/swd/btree/btree.html ,這個學校用圖案來表示當 B-tree 新增和刪除節點後是如何保持平衡的.
以外,B-tree 還有一些小變形,如 B+ tree,它是在 leaf 之間再加上一個 pointer 可以從一個 leaf 到下一個 leaf,這樣做的好處是我們可以在找到資料後,很快地再移到下一個資料而不需要每次都從 root 出發.我想這應該是大部份資料庫產品會採用的資料結構.
希望透過這篇文章的說明能讓你對資料庫 index 為什麼能為你快速找到資料有幫助.在了解了基本的原理之後,相信以後你在操作資料庫設定 index 時,心裡會有一種踏實的感覺,因為你知道資料庫引擎對這項工作運行時的基本原理了.
看了前面的文章後,想必你也可以很容易猜出 index 所使用的是像 tree 那樣的資料結構.在前面的文章中也談到了最基本的 tree 資料結構概念.tree 其實在電腦科學的領域裡應用的相當廣泛,不論是學術上或工業界裡,因為 tree 帶來的好處實在很多,但要把 tree 寫出來其實也不是一件很容易的事.不同的應用會衍生出不同的 tree,而在資料庫的 index 所採用的 tree 叫做 B-tree.所謂的 B 就是平衡 balance 這英文字,所以中文你可以用平衡樹來叫它.
B-tree 所指的平衡是指樹的每一個 leaf 到 root 都是一樣的高度,所以整顆樹看起來站的很穩,不會有缺一角的感覺.
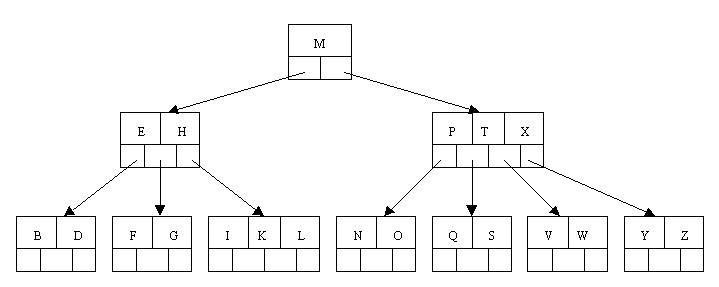 |
| source: http://cis.stvincent.edu/html/tutorials/swd/btree |
接下來的問題就是,我們怎麼會知道這顆樹會一直平衡呢 ? 這並不是資料庫引擎所要擔心的事情,因為保持平衡是 B-tree 本身就要具有的能力,也就是說當一個新的節點新增到這顆樹來後,樹的平衡機制就要啟動來調整樹本身的結構以保持平衡,同樣地刪除節點也是.所以,要實做 B-tree 的重點就是要看保持 "平衡" 的程式碼是不是寫的夠好.在這裡,我就不談論太多保持平衡的細節,若你有興趣知道 B-tree 是如何保持平衡的,可以參考 http://cis.stvincent.edu/html/tutorials/swd/btree/btree.html ,這個學校用圖案來表示當 B-tree 新增和刪除節點後是如何保持平衡的.
以外,B-tree 還有一些小變形,如 B+ tree,它是在 leaf 之間再加上一個 pointer 可以從一個 leaf 到下一個 leaf,這樣做的好處是我們可以在找到資料後,很快地再移到下一個資料而不需要每次都從 root 出發.我想這應該是大部份資料庫產品會採用的資料結構.
希望透過這篇文章的說明能讓你對資料庫 index 為什麼能為你快速找到資料有幫助.在了解了基本的原理之後,相信以後你在操作資料庫設定 index 時,心裡會有一種踏實的感覺,因為你知道資料庫引擎對這項工作運行時的基本原理了.







