出神入化這詞用的誇張了,為何選用這詞呢? 在 2016 年底辦了一個
.Net公益課程,課後的問卷裡詢問未來若有機會,大家有興趣聽什麼主題的內容.結果有位朋友寫了 "出神入化的用介面".我想這應該是當天課程上曾提到跟 Interface 有關的事情.後來,我想了想,這主題要描述的清楚並不是件容易的事,也不是三兩句話可以交待的完.所以,用一個說故事的方式來說明這個主題.透過這個主題可以一直延伸到許多程式設計和軟體開發上的事情.
如果你在業界有多年的軟體開發經驗,相信你對 Interface 一定有某種程度以上的使用與了解.但如果你現在還是一個在學的學生或是剛進入職場沒多久的社會新鮮人,也許你對 Interface 的了解可能只限於課本上或是老師口授而來的知識.由於 Interface 這種東西並不是什麼學術研究的題材 (應該說這是很舊的題材了),再加上許多學校裡的教授大部份很少有大量的產業界開發經驗,因此你能從課本或老師那邊得到的了解便是相當有限的.不論你是在業界打滾多年的好手或是剛進入職場沒幾年的菜烏,先來讓我們一起回想一下當初在學校裡上的物件導向程式語言的課程.也許許多人在學校並沒有上過這門課或是學校沒有開這門課,可能是一邊工作一邊看書學習.不論是那一種方式,我相信你一定都看到課程上或書本上介紹 Interface.當你看了 Interface 之後,你覺得你有什麼感覺嗎 ?
老實話,我以前在學校學的時候,還真的沒掌握到重點.只是覺得奇怪,為什麼要多弄一個 Interface,感覺上好像多了一個用不到的東西.其實,後來才發現,並不是用不到,只是還不會用而己.在物件導向式程式設計的世界裡,你一定都知道什麼是 Class,也一定知道什麼是 Object.這關係就有點像關聯式 (Entity relational model) 資料庫裡的 table schema 與 table 裡的資料.舉個例子,在資料庫中建立一個表格時,你一定會告訴資料庫引擎你需要的表格是長什麼樣子.如一個 int 欄位,一個 varchar(50) 欄位,以及一個 boolean 欄位.因此,你能寫入的資料一定要符合這個 table schema 的定義.相同的感覺,當你的 Class 定義好它的長相時,之後依這個 Class 建立出來的 Object 裡面的內容值也一定符合這個 Class 的定義.在資料庫設計中,表格和表格之間可以建立所謂的一對一或一對多等等的關係,同樣的在 Class 和 Class 之間也可以設計出這樣的關係.物件導向式模型有一個東西是關聯式模型裡面所沒有的,那就是 Interface.
Interface 和 Class 都是用來定義 Object 要長成什麼樣子.如下面看到的簡單例子.
class IAmAClass {
public int Id { get; set;}
public string Name { get; set;}
}
在撰寫程式時,你可以直接透過 new 這關鍵字來告訴電腦你需要一個記憶體空間來放一個依照 IAmAClass Class 長相所建立出來的 Object,如下
IAmAClass cls1 = new IAmAClass();
IAmAClass cls2 = new IAmAClass();
依照上面的程式碼,此時記憶體裡面有兩個 IAmAClass objects, 一個名字叫 cls1,另一個叫 clas2.這兩個 objects 是依照 IAmAClass 的長相所建立出來的,所以當我想要操作這兩個 objects 時,我就知道他有那些公開的屬性和方法可以使用.這些是最基本的事情,相信你一定知道.接下來,那 Interface 呢 ? 前面說了,Interface 和 Class 都是用來定義 object 要長成什麼樣子,那我們能直接定義一個 Interface 透過 new 關鍵字來建立 object 嗎? 很可惜,似乎不行.Interface 和 Class 好像蠻像的,但 Interface 卻不能直接透過 new 關鍵字來建立 object,這其中一定是有什麼設計上的考量!
相信你以前也想過這樣的問題.Interface 的用途很多,在第一集的文章裡,我先提出一個用途讓你看到為什麼有 Interface 的存在是比較好的.
假設,你的公司有好幾個部門,每個部門做的工作都是獨立又相依,意思就是說你要達成某項任務時,必須要使用其它部門的程式.舉例來說,你做的是一個寄信的程式,但信件的內容是根據各部門的需求而產生的,你不負責信件內容的產生,你只負責做寄信的動作.此時,A部門告訴你它的信件內容是 MailAContent class,它的長相如下 (細節忽略):
class MailAContent {
public string ReceipentEmail { get; set;}
public string HtmlContent { get; set;}
public string Subject { get; set;}
public bool Importance { get; set;}
}
於是,當你寫寄信程式時,你必須要拿到 MailAContent class 的定義,也就是說你得把對方的 dll 加入到你的程式專案裡,因為要這麼做,你的程式才能明白什麼是 MailAContent class.因此,當你在製做寄信程式時,你的程式某個片段可能會長成如下:
public void SendEmail(MailAContent mail) {
EmailServer server = new EmailServer();
server.IP = "1.1.1.1";
server.Username = "admin";
server.Password = "password";
server.Connect();
server.Send(mail.ReceipentEmail, mail.HtmlContent, mail.Subject, mail.Importance); // 假設寄信程式只需要知道這四個資料
server.Close();
}
到目前為止,看起來似乎合理.接下來,B部門也會產生 email,也要透過你的寄信程式來把信寄出去.但 B部門有自己的 email class,叫 MailBContent class,長相如下:
class MailBContent {
public string ReceipentEmail { get; set;}
public string HtmlContent { get; set;}
public string Subject { get; set;}
public bool Importance { get; set;}
}
於是你為了要把 B部門的 email 寄出去,你也寫了以下的程式在你的寄信程式中.
public void SendEmail(MailBContent mail) {
EmailServer server = new EmailServer();
server.IP = "1.1.1.1";
server.Username = "admin";
server.Password = "password";
server.Connect();
server.Send(mail.ReceipentEmail, mail.HtmlContent, mail.Subject, mail.Importance);
server.Close();
}
結果看到這程式,發現有點蠢,這麼多重覆目的的程式碼,於是進行了一個小小的 refactor :
public void SendEmail(MailAContent mail)
{
SendEmailInternal(mail.ReceipentEmail , mail.HtmlContent , mail.Subject, mail.Importance);
}
public void SendEmail(MailBContent mail)
{
SendEmailInternal(mail.ReceipentEmail , mail.HtmlContent , mail.Subject, mail.Importance);
}
private void SendEmailInternal(string receipent, string content, string subject, bool importance) {
EmailServer server = new EmailServer();
server.IP = "1.1.1.1";
server.Username = "admin";
server.Password = "password";
server.Connect();
server.Send(receipent, content, subject, importance);
server.Close();
}
經過小小的 refactor 之後,你會覺得程式碼好像比較沒那麼蠢了.但接下來, C部門,D部門相繼地把需求提過來,而你也發現每個部門的 email class 都是不一樣的 class,因此你就能想像你的寄信程式就要為 C部門再多弄一個 SendEmail(), 也要再為 D部門再多弄一個 SendEmail(),如果有十個部門而且每個部門的 email class 都不一樣,那麼你就得有十個 SendEmail(),這時你應該會發現程式碼真的有點蠢了.除此之外,因為你寫的寄信程式是要提供給其他部門使用,讓他們的程式碼呼叫你的 SendEmail() 才能寄信.此時,你會發現因為你的寄信程式 reference 每個部門的 email class,所以使得每個部門都要 reference 其他部門的 email class 才能正確地 compile.這真的是相當蠢的一件事.透過這個例子也剛好說明了 Class 真的是軟體開發的一個麻煩源頭之一.
從上面的例子來看,你會發現如果每一個部門都採用相同的 email class 的話,那不就好了嗎? 可能的做法是把 email class 定義在某一個共享元件裡,然後要求每個部門都 reference 這一個共享元件以使得用到相同的 email class.理論上,這是一個可行的方法.在這個例子裡,email class 只是一個很簡單的 data structure,沒有任何 implementation code.如果今天遇到的是一個有 implementation code 的 email class 時,就會遇到一個小麻煩,它就是當這個 email class 改版時 (修改 implementation code),就得通知所有部門更新這一個共享元件.除了這方法以外,你還可以用 Interface.
如前面所說,Interface 和 Class 都是用來定義 Object 要長成什麼樣子,但 Interface 不能用來建立 object,卻可以用來表達一個 object 是否具有其他的 "特定長相". 在元件之間的互動,認定的是長相而不是真正的 object 是什麼,並且放在共享元件裡的是 Interface 而不是 implementation code,因此 email class 改版時,共享元件不需要更新,只有在 interface 改版時才需要更新共享元件.
因此,以上述的例子來說,在共享元件的 interface 長成這樣:
Interface IMailContent {
string ReceipentEmail { get; }
string HtmlContent { get; }
string Subject { get; }
bool Importance { get; }
}
以 A部門來說,它的 email class 改成如下:
class MailAContent : IMailContent
{
public string ReceipentEmail { get; set;}
public string HtmlContent { get; set;}
public string Subject { get; set;}
public bool Importance { get; set;}
}
MailAContent class 使用了 IMailContent,這表示 MailAContent class 一定要有 IMailContent 裡所有成員的 implementation code.一旦 MailAContent class 被建立成 object 時,這個 object 既是 MailAContent 也是 IMailContent,也就是說這個 object 有著兩種 data type 的感覺,這樣說不精確,但感覺起來像是如此.接著,寄信程式可以改成如下:
public void SendEmail(IMailContent mail) {
EmailServer server = new EmailServer();
server.IP = "1.1.1.1";
server.Username = "admin";
server.Password = "password";
server.Connect();
server.Send(mail.receipent, mail.content, mail.subject, mail.Importance);
server.Close();
}
當 SendEmail() 被 A部門呼叫時,傳進來的 IMailContent 其實是 MailAContent object,因為這個 object 實做了 IMailContent ,所以這樣傳進來並不會有什麼問題.在 SendEmail() 裡面只認得 IMailContent 的長相,因此在 SendEmail() 存取該物件的成員時,只能用那些 "看" 的到的成員,也就是 IMailContent 上有的成員.同理,當 SendEmail() 被 B部門呼叫時,傳進來的 object 是 MailBContent object,也因為此 object 實做 IMailContent,所以 SendEmail() 執行時不會造成問題.以推類推,所有部門的 email class 都實做了 IMailContent,這樣寄信程式只要一個 SendEmail() 就可以,這樣不是更好嗎?
也許以上寄信這個例子不是很精準,但也把最基本的 Interface 應用呈現出來.如果你還沒機會參與多部門或多人開發的軟體專案,Interface 其實仍是重要的.因為它不僅用在跨部門的情況下相當好用,而且也能幫助你做更好的 unit test.
這集的重點是:
- Interface 和 Class 都是用來定義 Object 要 "長" 成什麼樣子,但 Interface 不參與 implementation,只專心定義一個 object 能 "長" 成什麼樣子.Interface 提供了 object 一種 "外衣",不同的 email content object 只要有相同的 "外衣" (IMailContent),都可以在 SendEmail() 裡面使用.一個 object 可以有多個 "外衣",因此使得物件導向程式設計變得很彈性也很有趣.
- 當你要使用別人的 Class 時很可能會造成麻煩,應盡量使用 Interface.以上的故事也告訴你當你把一個 class 建立成一個 object 時,這其實就是許多問題的根源之一.




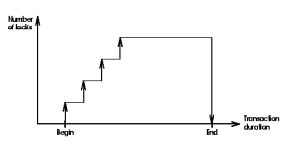






 資料來源: 我以前在學校的筆記
資料來源: 我以前在學校的筆記 資料來源: 我以前在學校的筆記
資料來源: 我以前在學校的筆記 資料來源: 我以前在學校的筆記
資料來源: 我以前在學校的筆記
