在第二集的內容中,我們用了一個極為簡化的例子來說明物件如何在大型軟體系統中移動.當時的做法是在 CommonLibrary 裡放了一個 static 的 Dictionary,讓各元件把自己實做好的物件「存」進去,其他元件再從這個 Dictionary 裡「取」出來使用.透過這樣的方式,ClassLibrary1 和 ClassLibrary2 彼此不需要互相認識 (不需要加 reference),就能使用對方所提供的功能.
這個做法雖然簡單好懂,但如果你在實際的專案中也這樣做的話,隨著系統越來越大,你會發現幾個問題:
第一,你必須自己管理這個 Dictionary,包括什麼時候該把物件放進去,key 要用什麼字串,以及取出來的時候要記得做型別轉換.第二,每個團隊都必須知道這個 Dictionary 的存在,並且要遵守一些潛規則,例如 key 不能重複,放入的順序不能搞錯等等.第三,當物件之間的相依關係越來越複雜時,手動管理這些註冊和取用的程式碼會變得相當繁瑣且容易出錯.
那麼,有沒有什麼方法可以把這些手動管理的工作交給別人來做呢?答案就是這一集要談的主題:Dependency Injection (DI).
先回顧第二集的做法
在第二集裡,CommonLibrary 提供了一個 ObjectContainer,裡面有一個 Dictionary 來儲存各元件的物件:
public class ObjectContainer
{
public static Dictionary<string, IOperation> Operations = new Dictionary<string, IOperation>();
public static Dictionary<string, Form> Dialogs = new Dictionary<string, Form>();
}
然後各元件在啟動時把自己的物件註冊進去:
// ClassLibrary2 的註冊
public static class Starter
{
public static void Register()
{
ObjectContainer.Operations["operation2"] = new Operation2();
ObjectContainer.Dialogs["library2"] = new Lib2WinForm1();
}
}
最後在 WindowsFormsApp1 啟動的時候呼叫各元件的註冊方法:
static void Main()
{
ClassLibrary1.Starter.Register();
ClassLibrary2.Starter.Register();
Application.Run(new Form1());
}
而 ClassLibrary1 要使用 ClassLibrary2 的功能時,就去 Dictionary 裡撈:
if (ObjectContainer.Operations.TryGetValue("operation2", out IOperation op))
{
int result = op.AddIntOperation(5);
}
如果你仔細看這整個流程,你會發現它其實做了三件事情:第一,定義一份 interface 作為雙方的合約 (contract);第二,提供一個容器 (Dictionary) 來存放物件;第三,在程式啟動時把物件註冊到容器裡.這三件事情就是 Dependency Injection Container 的核心概念.換句話說,第二集的做法就是一個最原始的、手動版的 DI Container.
什麼是 Dependency Injection
Dependency Injection 這個名字聽起來很嚇人,但其實概念非常簡單.所謂的 "Dependency" 就是一個物件所依賴的其他物件.所謂的 "Injection" 就是把這個依賴的物件「注入」到需要它的地方.
舉個日常生活的例子,你去餐廳吃飯,你不需要自己跑到廚房去拿菜,服務生會把菜端到你的桌上.在這個比喻裡,菜就是你的 dependency,服務生把菜端給你就是 injection,而餐廳的出菜系統就是 DI Container.你只需要告訴服務生你要什麼菜 (透過菜單,也就是 interface),至於這道菜是哪個廚師做的、用什麼鍋子、幾點開始煮的,你完全不需要知道.
回到程式的世界,在第二集的做法裡,ClassLibrary1 要使用 IOperation 時,必須自己去 Dictionary 裡面找,要知道 key 是什麼,還要做型別的判斷.這就好像你去餐廳吃飯,還得自己走到廚房去翻鍋子找你點的菜一樣.而 DI 的做法則是讓框架自動把 IOperation 的實作送到 ClassLibrary1 手上,ClassLibrary1 只需要說「我需要一個 IOperation」就好了.
自己動手做一個簡單的 DI Container
在談現成的 DI 框架之前,讓我們先自己動手做一個極為簡化的 DI Container,這樣你就能完全理解它的運作原理.其實它的本質就是一個用 Type 當作 key 的 Dictionary,取代第二集裡用字串當作 key 的 Dictionary:
public class SimpleDIContainer
{
// 用 Type 當作 key,存放的是「如何建立這個物件」的方法
private Dictionary<Type, Func<object>> _registrations
= new Dictionary<Type, Func<object>>();
// 註冊: 告訴 Container 「當有人要 TInterface 時,請建立 TImplementation」
public void Register<TInterface, TImplementation>()
where TImplementation : TInterface, new()
{
_registrations[typeof(TInterface)] = () => new TImplementation();
}
// 取得: 根據 interface 的型別,自動建立並回傳對應的實作
public TInterface Resolve<TInterface>()
{
if (_registrations.TryGetValue(typeof(TInterface), out var factory))
{
return (TInterface)factory();
}
throw new Exception($"Type {typeof(TInterface).Name} is not registered.");
}
}
這個 SimpleDIContainer 做的事情和第二集的 ObjectContainer 非常相似,但有一個關鍵的不同:它用 Type 來當 key,而不是字串.這表示你不再需要記住每個物件對應的字串是什麼,也不會因為打錯字而導致找不到物件.
接著來看看怎麼用它.首先是註冊的部分:
static void Main()
{
var container = new SimpleDIContainer();
// 告訴 Container: 當有人需要 IOperation 時,請給他 Operation2 的實體
container.Register<IOperation, Operation2>();
// 取得 IOperation 的實作
IOperation op = container.Resolve<IOperation>();
int result = op.AddIntOperation(5); // result = 7
}
對比一下第二集的做法:
// 第二集: 用字串當 key,手動放入和取出
ObjectContainer.Operations["operation2"] = new Operation2();
ObjectContainer.Operations.TryGetValue("operation2", out IOperation op);
// 這一集: 用 Type 當 key,透過泛型自動對應
container.Register<IOperation, Operation2>();
IOperation op = container.Resolve<IOperation>();
你可以看到,核心概念一模一樣,都是「先存再取」,只是手段從字串對應變成了型別對應,讓編譯器可以在編譯時就幫你檢查型別是否正確,不用等到執行時期才發現字串打錯.
讓 Container 自動注入到建構子
上面的 SimpleDIContainer 雖然已經比手動 Dictionary 好了一些,但使用者還是得自己呼叫 Resolve 來取得物件.真正的 DI 精神是讓 Container 自動把 dependency 注入到需要它的地方.最常見的方式就是透過建構子 (constructor) 來注入.
我們把 SimpleDIContainer 稍微加強一下,讓它能夠分析建構子的參數,並且自動注入對應的物件:
public class DIContainer
{
private Dictionary<Type, Type> _registrations = new Dictionary<Type, Type>();
public void Register<TInterface, TImplementation>()
where TImplementation : class, TInterface
{
_registrations[typeof(TInterface)] = typeof(TImplementation);
}
public T Resolve<T>()
{
return (T)Resolve(typeof(T));
}
private object Resolve(Type type)
{
// 如果有註冊,就找到對應的實作型別
if (_registrations.TryGetValue(type, out Type implementationType))
{
return CreateInstance(implementationType);
}
// 如果沒有註冊但本身是可建立的類別,也嘗試建立
if (!type.IsAbstract && !type.IsInterface)
{
return CreateInstance(type);
}
throw new Exception($"Type {type.Name} is not registered.");
}
private object CreateInstance(Type type)
{
// 找到建構子
var constructor = type.GetConstructors().First();
// 取得建構子的參數型別,並且遞迴地解析每一個參數
var parameters = constructor.GetParameters()
.Select(p => Resolve(p.ParameterType))
.ToArray();
// 用解析好的參數來建立物件
return Activator.CreateInstance(type, parameters);
}
}
這個加強版的 Container 會做一件很重要的事:當它要建立一個物件時,它會去看這個物件的建構子需要哪些參數,然後遞迴地把每一個參數對應的物件也建立出來並且注入進去.
於是 ClassLibrary1 的程式碼可以寫成這樣:
public class Lib1WinForm1 : Form
{
private readonly IOperation _operation;
// Container 會自動把 IOperation 的實作注入到這個建構子
public Lib1WinForm1(IOperation operation)
{
_operation = operation;
InitializeComponent();
}
private void button2_Click(object sender, EventArgs e)
{
// 直接使用,不需要再去 Dictionary 裡面找
int i = 5;
richTextBox1.Text += $"int starts at {i}\n";
i = _operation.AddIntOperation(5);
richTextBox1.Text += $"int becomes {i} after Operation2\n";
string s = "aBc";
richTextBox1.Text += $"string starts as {s}\n";
s = _operation.ChangeStringOperation(s);
richTextBox1.Text += $"string becomes {s} after Operation2";
}
}
注意看 Lib1WinForm1 的建構子,它宣告了一個 IOperation 的參數.當 DI Container 要建立 Lib1WinForm1 的時候,它會看到這個建構子需要一個 IOperation,於是就自動去找已經註冊好的 Operation2 來注入.這就是 "Dependency Injection" 這個名字的由來.
對比第二集的做法,ClassLibrary1 不再需要知道 Dictionary 的 key 是什麼字串,不需要做 TryGetValue,也不需要處理找不到的情況.它只需要在建構子裡說「我需要一個 IOperation」,Container 就會自動把正確的實作塞給它.這就像你在餐廳只需要看菜單點菜,不需要自己去廚房找菜一樣.
三種常見的注入方式
上面的例子是透過建構子來注入,這是最常見也是最推薦的方式,叫做 Constructor Injection.除此之外,還有另外兩種方式:
第一種是 Property Injection,就是透過設定屬性來注入:
public class Lib1WinForm1 : Form
{
// 透過 Property 注入
public IOperation Operation { get; set; }
}
第二種是 Method Injection,就是透過方法的參數來注入:
public class Lib1WinForm1 : Form
{
public void DoSomething(IOperation operation)
{
// 透過方法參數注入
int result = operation.AddIntOperation(5);
}
}
在實務上,Constructor Injection 是最被推薦的方式,因為它可以確保物件在被建立的時候就已經擁有它所需要的所有 dependency,不會有遺漏的情況.而且透過建構子的參數,你可以一眼就看出這個類別依賴了哪些其他物件,程式碼的意圖很明確.
物件的生命週期
在第二集的做法中,我們把 Operation2 的實體放進 Dictionary 以後,它就一直待在那裡直到整個程式結束.但在真實的系統中,不同的物件可能需要不同的生命週期.有些物件只需要一個就夠了 (例如設定檔的管理),有些物件每次使用都需要一個新的 (例如資料庫的連線),還有些物件在同一個請求範圍內需要共用同一個實體.
一般來說,常見的 DI Container 都會提供以下三種生命週期的管理:
Singleton: 整個應用程式只會建立一個實體,所有人共用同一個.以第二集的做法來說,物件放進 Dictionary 之後就不會再變了,所以等同於 Singleton 的概念.
Transient: 每次有人要求時都建立一個全新的實體.如果你的物件有狀態,而且不同的使用者不應該共用這個狀態,就適合使用 Transient.
Scoped: 在同一個範圍內共用一個實體,離開這個範圍後就銷毀.例如在一個 Web 應用中,同一次 HTTP Request 裡面的所有程式碼共用同一個實體,下一次 Request 進來時再建立一個新的.
如果你的系統需要更細膩的生命週期控管,手動用 Dictionary 來管理就會變得很痛苦,這時候 DI Container 的價值就顯現出來了.
Interface 在 DI 中扮演的角色
從第一集到第二集再到現在,Interface 一直都是整個架構的核心.它的角色就是定義合約 (contract),讓提供服務的一方和使用服務的一方之間有一份共同的協議,而雙方不需要直接認識彼此.
在 DI 的架構中,Interface 更是不可或缺的角色.因為 DI Container 的運作原理就是:你告訴 Container「當有人要求 Interface A 的時候,請提供 Class B 的實體」.Container 就像是一個仲介,它認識所有的 interface 和實作之間的對應關係,而使用者只需要跟 Container 說他需要什麼 interface,Container 就會在 runtime 時把正確的實作注入進去.
這樣做最大的好處就是,如果有一天 ClassLibrary2 團隊決定把 Operation2 替換成 Operation2V2,只需要改一行註冊的程式碼就好:
// 原本 container.Register<IOperation, Operation2>(); // 替換成新版本,只改這一行 container.Register<IOperation, Operation2V2>();
ClassLibrary1 團隊的程式碼完全不需要改動,因為它從頭到尾只認識 IOperation 這個 interface,至於背後是誰實做的,它不知道也不需要知道.在第二集的做法中,如果要替換實作,你也需要改一行程式碼,但你還得確保 Dictionary 的 key 沒有變、其他使用這個 key 的地方也都要對應到,這些在大型系統中是容易出差錯的地方.
從手動管理到自動管理
讓我們把第二集和這一集做一個對照,你會更清楚看到兩者之間的關係:
在第二集中,CommonLibrary 提供了 ObjectContainer (一個用字串當 key 的 Dictionary),各元件在啟動時手動將自己的物件註冊到 Dictionary 裡,使用的一方再手動從 Dictionary 裡用字串取出物件來用.這整個流程中的「註冊」和「取用」都是手動完成的.
而在 DI 的做法中,DI Container 用 Type 來當 key (取代字串),各元件透過泛型方法來註冊 interface 和實作的對應關係,使用的一方只需要在建構子宣告 interface 參數,Container 就會在 runtime 自動注入正確的實作.「註冊」仍然是手動的 (你需要告訴 Container 誰對應誰),但「取用」變成自動的了.
所以本質上,DI Container 就是一個進化版的 Dictionary,它把第二集中我們手動做的事情包裝起來,讓整個流程更自動化、更不容易出錯、也更好維護.
實務上的 DI 框架
上面我們自己手寫了一個簡化版的 DI Container 來說明原理,但在實務的專案中,你不需要自己造輪子,幾乎所有主流的程式語言和框架都有提供現成的 DI Container 可以直接使用.
在 C# 的世界裡,除了框架本身內建的 DI 機制以外,也有像 Autofac、Ninject、Unity 等老牌的 DI Container 套件可以選擇,它們各自提供了更多進階的功能,如自動掃描組件來註冊、模組化的註冊、攔截器 (interceptor) 等.在 Java 的世界裡,Spring Framework 的 IoC Container 是最經典的代表,它的概念和我們今天談的完全一樣.在 Python 中也有像 dependency-injector 這類的套件.不管是哪一種語言或框架,DI 的核心精神都是一樣的:透過 interface (或抽象類別) 定義合約,讓 Container 在 runtime 自動注入正確的實作.
值得一提的是,DI 和 IoC (Inversion of Control,控制反轉) 這兩個名詞常常被放在一起談.IoC 是一個比較抽象的設計原則,意思是「把控制權交出去」.在沒有 DI 的時候,一個物件需要什麼 dependency,它就自己去 new 一個出來,控制權在物件自己手上.而用了 DI 之後,物件不再自己建立 dependency,而是由外部 (Container) 來提供,控制權就「反轉」了.所以你可以把 DI 理解為實現 IoC 原則的一種具體做法.
小結
DI Container 帶來的好處包括:不需要手動管理 key 和 Dictionary、物件的生命週期可以被統一管理、替換實作只需要改一行註冊的程式碼、以及程式碼的可測試性大幅提升 (因為你可以很容易地在測試時注入 mock 物件).
如果你還沒有在專案中使用 DI,我會建議你從小地方開始嘗試.先在一個新的小功能中試著用 DI Container 來管理物件的建立和注入,慢慢地你就會體會到它的好處,然後你再也不會想回到手動管理 Dictionary 的日子了.
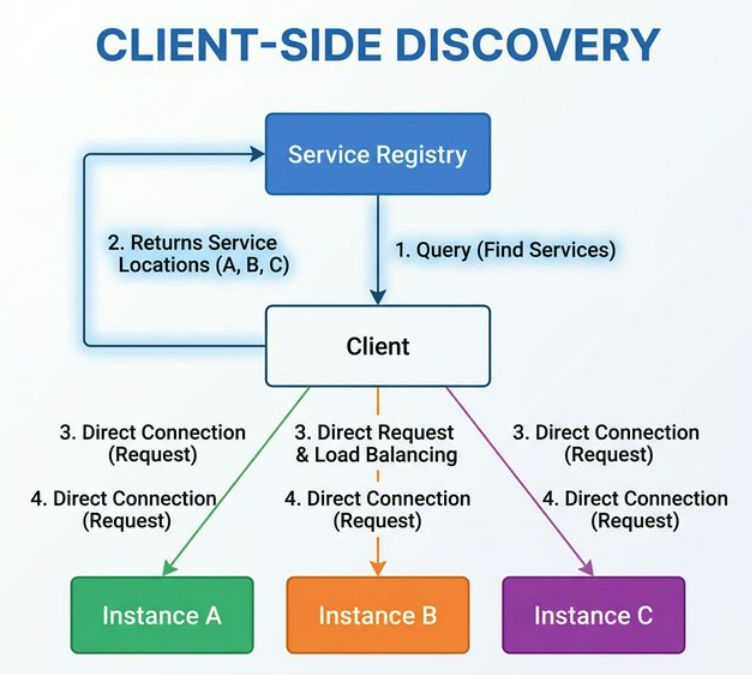 重點:Client 負責查詢 Registry、選擇 Instance、直接呼叫
重點:Client 負責查詢 Registry、選擇 Instance、直接呼叫
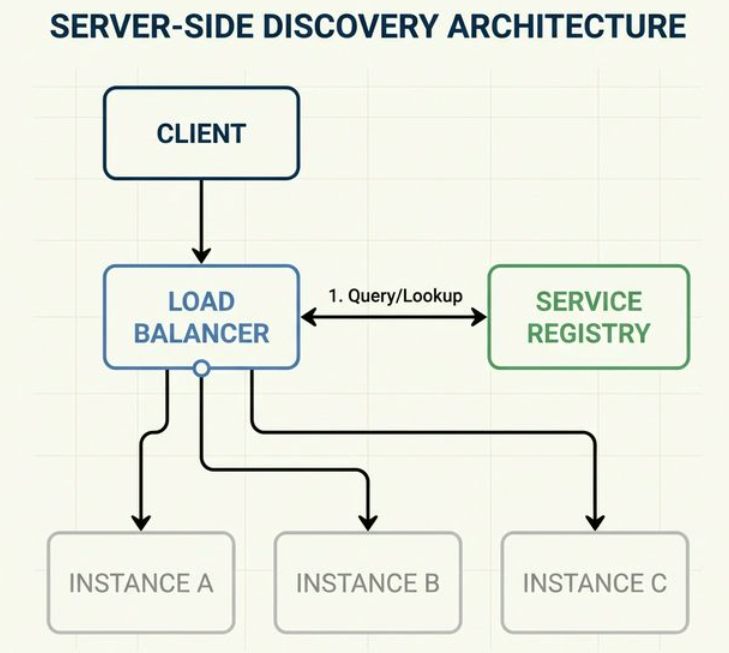 重點:Client 不知道 Instance 位址,由中間層負責路由,多一層 Network Hop,但 Client 邏輯簡單
重點:Client 不知道 Instance 位址,由中間層負責路由,多一層 Network Hop,但 Client 邏輯簡單
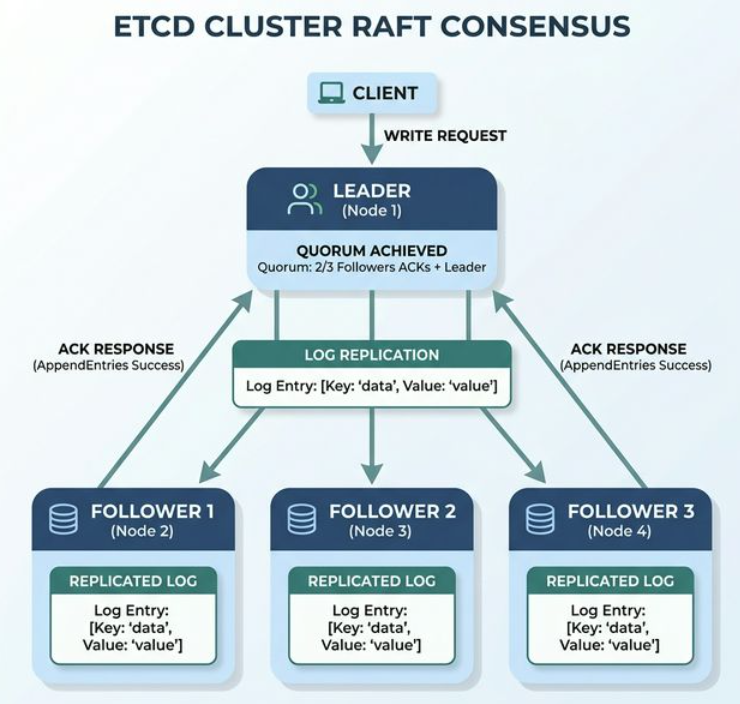 重點:寫入只能透過 Leader,超過半數 (Quorum) 確認即算成功,5 台掛 2 台仍可運作 (3 > 5/2)
重點:寫入只能透過 Leader,超過半數 (Quorum) 確認即算成功,5 台掛 2 台仍可運作 (3 > 5/2)
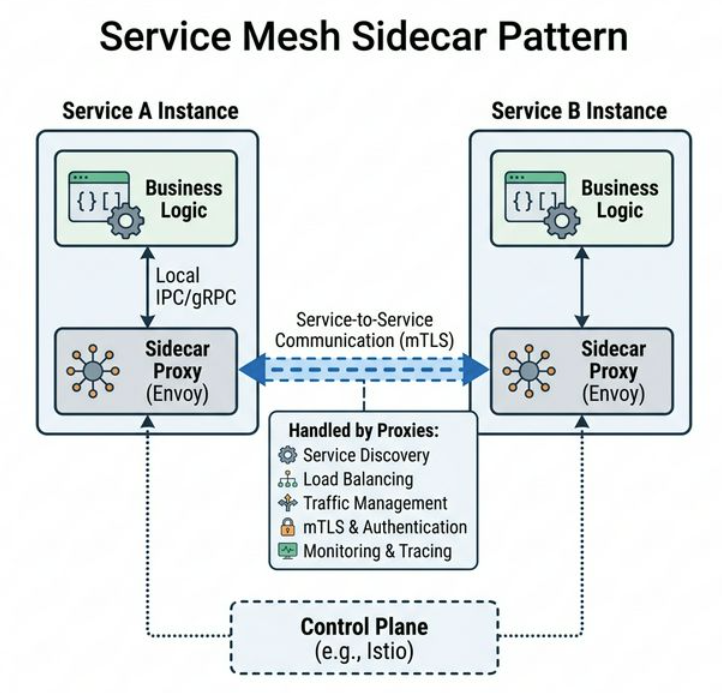 應用只管商業邏輯,網路通訊的一切交給 Sidecar Proxy,所有服務共用同一套基礎設施
應用只管商業邏輯,網路通訊的一切交給 Sidecar Proxy,所有服務共用同一套基礎設施
