在 binary tree 的文章時曾提到從 tree 開始後的資料結構文章將會開啟另一個大門,看來許多問題可以透過 tree 結構來解決.今天要介紹的 segment tree 就是一個例子.
試想一個情況,在現實生活中一定常常會遇到一個工作,一堆資料裡面,在某一個特定範圍依照某一個資料特徵來尋找資料.例如,在公司組織結構裡,找出 A 老闆底下的員工數總和.假設你已經有了員工組織樹狀結構,第一件要做的事情便是尋找 A 老闆節點,找到 A 老闆節點後,再從這裡出發將所有子節點計算個數,便能得到答案.一旦這樣的查詢工作常常發生的話,你會發現前面說的動作並不能馬上回應答案,因為還是要對員工組織樹狀結構進行 traversal 的動作.公司員工組織樹狀結構有一個特別的特性,員工的流動率正常來說都是小的.一家正常的公司不可能每天有很大比例的人員異動.公司員工組織樹狀結構不需要常常更新,並且需要更新時,也都是小比例的更新.當問題有這樣的特性時,segment tree 便是一個很好的資料結構用來解決這問題。
首先,為了簡單起見,讓我把上面描述的問題簡化,將人名變成一個數字的 array, 然後將非 leaf 的 node 變成是將兩個小孩節點之值的總和,因此,相對應的題目就變成在這個 array 裡面某個連續的空間找出值的總和。這個過程是一個特別的 reduction,專為這個題目做的一個轉換。
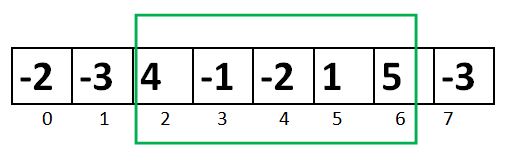
Segment tree 是一種 binary tree,它的 leaf node 就是 array element 的值,如下圖,

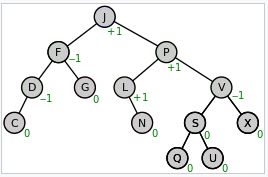
將它製做成 segment tree,其長相如下,

在中間節點的值就是底下兩個小孩節點的值總和。所以,在上圖中最左邊的 leaf node 是14 和15,他們的上一層節點就是14+15=29,依此類推。同時,在每個節點裡有一個特別的資料,用橘色來表示。橘色的字串代表的是一組位置,array 的index 編號的開始編號與結束編號。例如,上面提的29節點,它的橘色字串為1-2,代表了29的值是從array element 的第一個加到第二個,依此類推。再舉個例子,當你需要第三個到第六個的值時,你只需要找到兩個節點,3-4和5-6這兩個,就可以得到答案。當這個 segment tree 變得很大時,就省下了不少 traversal 步驟,以節省時間。
當 array 的某一個 element 的值改變了時,也只需要更新這個 leaf node 往上的值,一路更新到 root 即可,並不是全部的 tree node 都要更新。
以上談的 segment tree 雖然是用數字來作為例子,但實務上是可以有許多變化的,例如,每個node 的值不一定是數字,也可以是其他種類的資料型別,只要在往上資料彙聚的過程中可以用一個不複雜的方式將下一層的資料會聚在一起寫在上一層的結果。同時,這些結果一定要對你需要的搜尋結果有意義就行了。
Hope it helps,




 source: Wikipedia
source: Wikipedia
 source: www.tutorialspoint.com
source: www.tutorialspoint.com source: www.tutorialspoint.com
source: www.tutorialspoint.com source: www.tutorialspoint.com
source: www.tutorialspoint.com source: www.tutorialspoint.com
source: www.tutorialspoint.com